



喜讯:国内、香港、海外云服务器租用特惠活动,2核/4G/10M仅需31元每月,点击抢购>>>
百度智能云全功能AI开发平台BML-基于Notebook的图像分类模板使用指南
基于Notebook的图像分类模板使用指南
本文采用图像分类-单图单标签模板开发模型的过程为例,介绍从创建 Notebook 任务到引入数据、训练模型,再到保存模型、部署模型的全流程。
创建并启动Notebook
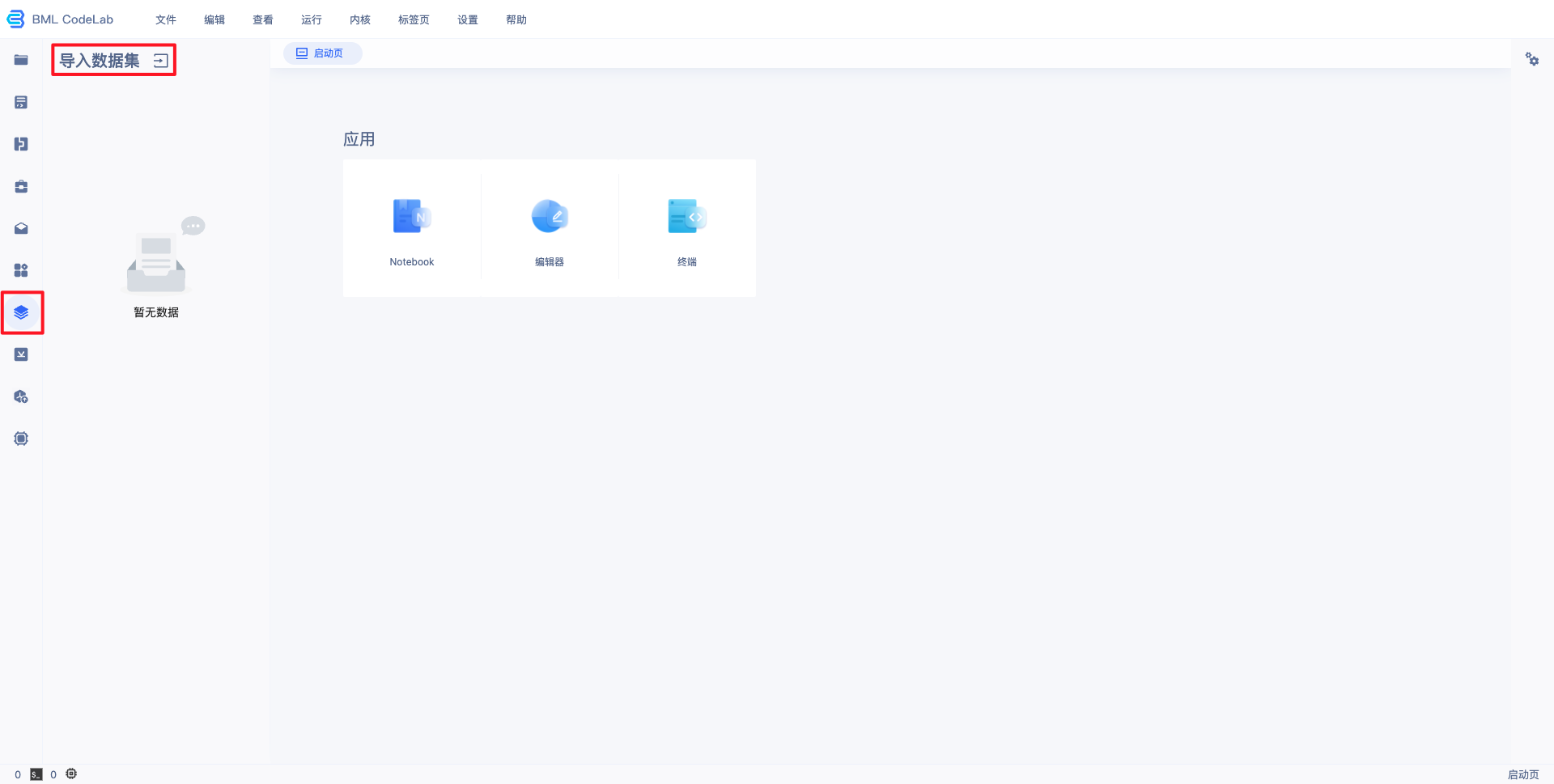
1、在 BML 左侧导航栏中点击『Notebook』
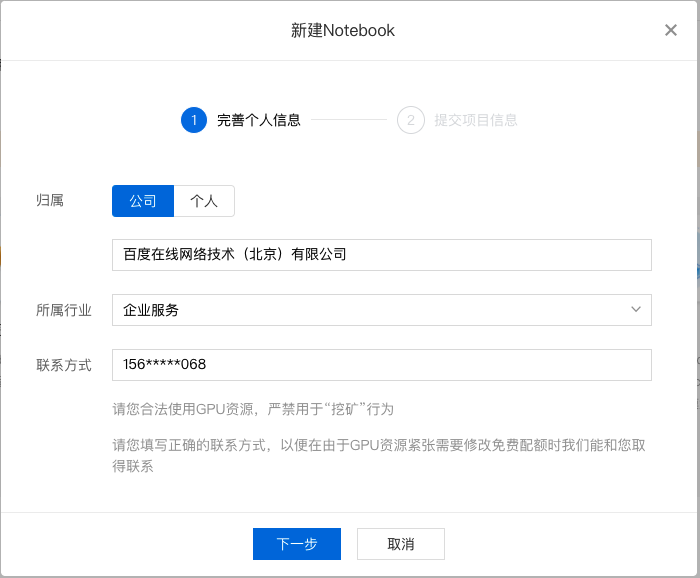
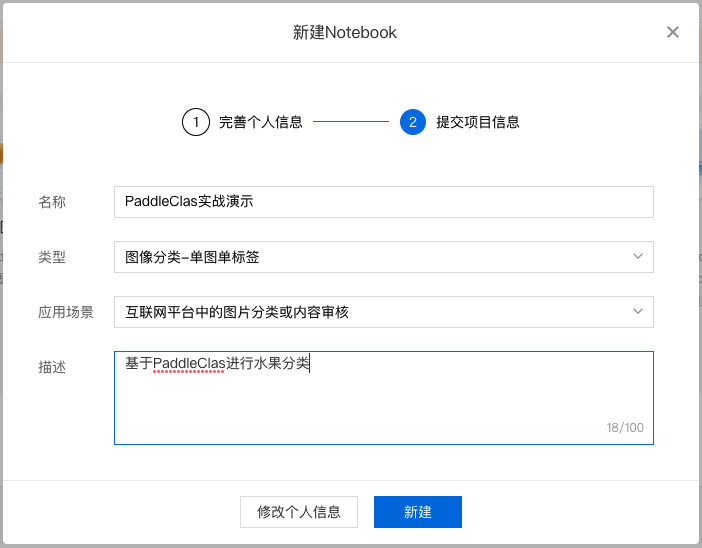
2、在 Notebook 页面点击『新建』,在弹出框中填写公司/个人信息以及项目信息,示例如下:
填写基础信息
填写项目信息
3、对 Notebook 任务操作入口中点击『配置』进行资源配置,示例如下:
选择开发语言、AI 框架,由于本次采用 PaddleClas 进行演示,所以需要选择 python3.7、PaddlePaddle2.0.0。选择资源规格,由于深度学习所需的训练资源一般较多,需要选择GPU V100的资源规格。
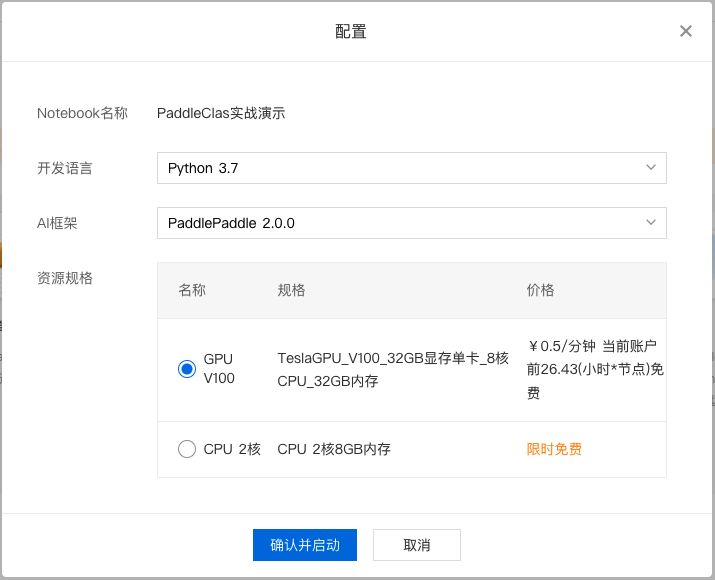
完成配置后点击『确认并启动』,即可启动 Notebook,启动过程中需要完成资源的申请以及实例创建,请耐心等待。
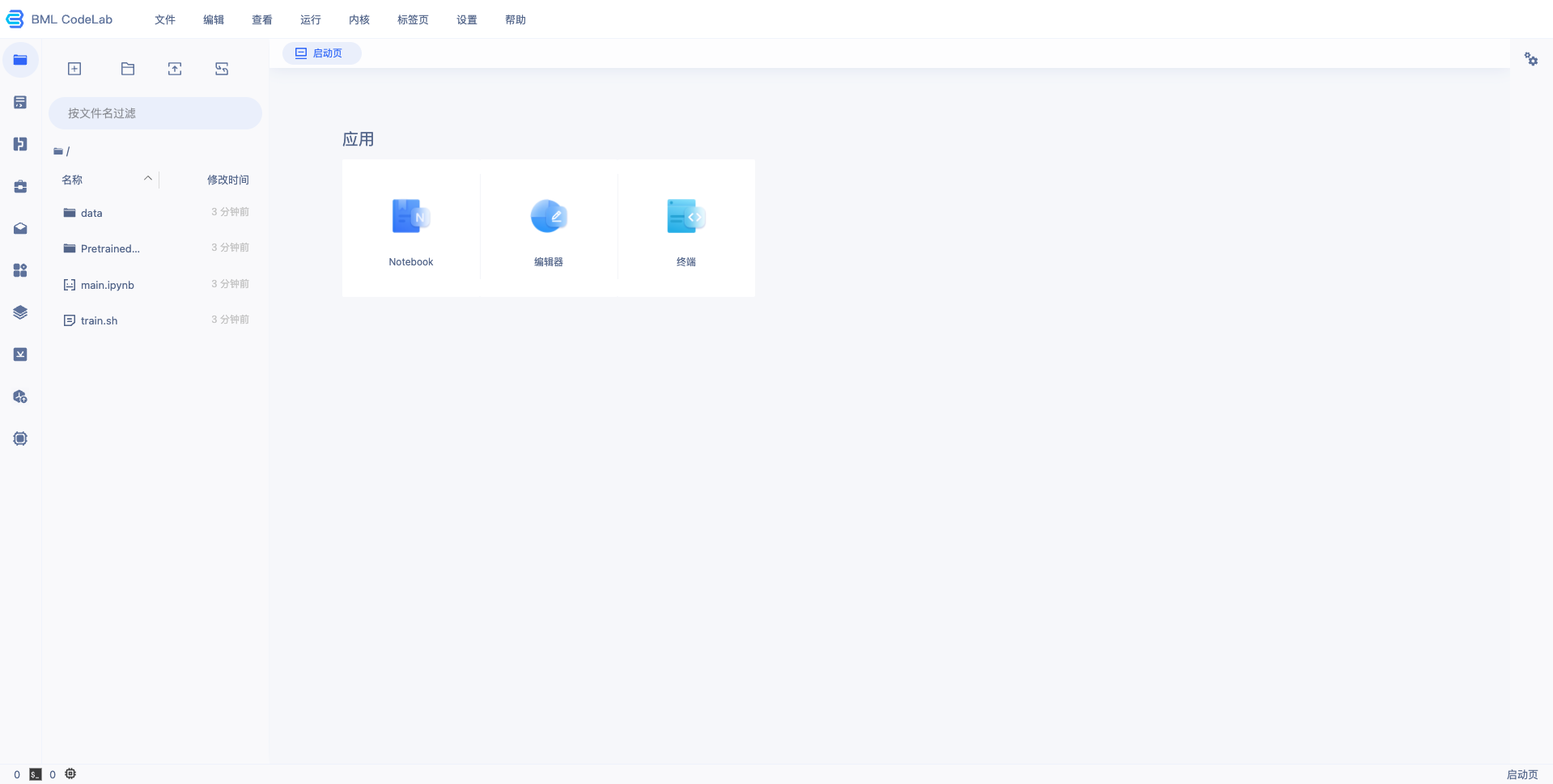
4、等待 Notebook 启动后,点击『打开』,页面跳转到 Notebook,即完成 Notebook 的创建与启动,示例如下:
训练图像分类-单图单标签模型
下载 PaddleClas 套件
打开进入 Notebook,点击进入终端,输入如下命令切换到 /home/work/ 目录。
cd /home/work/
本文以 PaddleClas 代码库 release/2.3 分支为例,输入如下命令下载并解压代码包。整个过程需要数十秒,请耐心等待。
wget https://github.com/PaddlePaddle/PaddleClas/archive/refs/heads/release/2.3.zip && unzip 2.3.zip
安装环境
在终端环境中,安装该版本的 PaddleClas 代码包依赖的 paddlepaddle-gpu,执行如下命令:
python -m pip install paddlepaddle-gpu==2.1.3.post101 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html
安装完成后,使用 python 或 python3 进入python解释器,输入 import paddle ,再输入 paddle.utils.run_check()
如果出现 PaddlePaddle is installed successfully!,说明成功安装。
准备训练数据
训练数据是模型生产的重要条件,优质的数据集可以很大程度上的提升模型训练效果,准备数据可以参考链接。本文所用的安全帽检测数据集可前往此链接进行下载:下载链接。
1、导入用户数据。
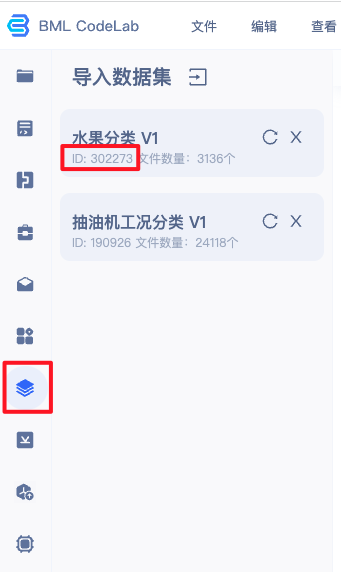
在 Notebook 中并不能直接访问您在 BML 中创建的数据集,需要通过左边选择栏的导入数据集选项,进行数据集导入。导入的数据位于用户目录的 data/ 文件夹(当原始数据集有更新时,不会自动同步,需要手工进行同步)。
注:若在BML中未创建数据集,请先参考 数据服务 ,创建、上传、标注数据集。
2、数据转换。
PaddleClas 训练所需要的数据格式与 BML 默认的数据格式有所不同,所以需要利用脚本将导入的数据转为 PaddleClas 支持的数据格式,并进行3:7切分。
PaddleClas 默认支持的标注格式为 txt,文件中每行格式如下:
图像相对路径 图像的label_id(数字类别)(注意:中间有空格)
转换脚本如下:
import osimport jsonimport globimport codecsimport randomdef parse_label_list(src_data_dir, save_dir):
"""
遍历标注文件,获取label_list
:param src_data_dir:
:return:
"""
label_list = []
anno_files = glob.glob(src_data_dir + "*.json")
for anno_f in anno_files:
annos = json.loads(codecs.open(anno_f).read())
for object in annos["labels"]:
label_list.append(object["name"])
label_list = list(set(label_list))
with codecs.open(os.path.join(save_dir, "label_list.txt"), 'w', encoding="utf-8") as f:
for id, label in enumerate(label_list):
f.writelines("%s:%s
" % (id, label))
return len(label_list), label_listdef trans_split_data(src_data_dir, save_dir):
"""转换数据格式,并3/7分切分数据"""
image_list = glob.glob(src_data_dir + "*.[jJPpBb][PpNnMm]*")
image_label_list = []
for image_file in image_list:
json_file = image_file.split('.')[0]+".json"
if os.path.isfile(json_file):
annos = json.loads(codecs.open(json_file).read())
label = annos["labels"][0]["name"]
image_label_list.append("{} {}
".format(os.path.basename(image_file), label_list.index(label)))
random.shuffle(image_label_list)
split_nums = int(len(image_label_list) * 0.3)
val_list = image_label_list[:split_nums]
train_list = image_label_list[split_nums:]
with open(os.path.join(save_dir, "train.txt"), 'w') as f:
f.writelines(train_list)
with open(os.path.join(save_dir, "val.txt"), 'w') as f:
f.writelines(val_list)
class_nums, label_list = parse_label_list("/home/work/data/${dataset_id}/", "/home/work/PretrainedModel/")trans_split_data("/home/work/data/${dataset_id}/", "/home/work/PretrainedModel/")将上述脚本存放为 coversion.py 代码脚本,并将脚本最后两行的 ${dataset_id} 替换为所指定数据集的 ID(下图红框中的ID),在终端中运行即可。
运行代码。
python coversion.py
运行之后将在 PretrainedModel/ 文件夹下生成对应的数据文件,包括 label_list.txt、tran.txt、val.txt。

训练模型
1、在终端中打开 PaddleClas 目录。
cd /path/to/PaddleClas
2、修改yaml配置文件。
本文以 ResNet50_vd 为例,配置文件路径为:
/home/work/PaddleClas-release-2.3/ppcls/configs/ImageNet/ResNet/ResNet50_vd.yaml
# global configsGlobal:
checkpoints: null
pretrained_model: null
output_dir: ./output/ # 使用GPU训练
device: gpu # 每几个轮次保存一次
save_interval: 1
eval_during_train: True
# 每几个轮次验证一次
eval_interval: 1
# 训练轮次
epochs: 10
print_batch_step: 10
use_visualdl: False #是否开启可视化
# used for static mode and model export
# 图像大小
image_shape: [3, 224, 224]
save_inference_dir: ./inference# model architectureArch:
# 采用的网络
name: ResNet50_vd # 类别数
class_num: 1000
# loss function config for traing/eval processLoss:
Train:
- CELoss:
weight: 1.0
epsilon: 0.1
Eval:
- CELoss:
weight: 1.0Optimizer:
name: Momentum momentum: 0.9
lr:
name: Cosine learning_rate: 0.1
regularizer:
name: 'L2'
coeff: 0.00007# data loader for train and evalDataLoader:
Train:
dataset:
name: ImageNetDataset # 数据集根路径
image_root: /home/work/data/${dataset_id}
# 前面生产得到的训练集列表文件路径
cls_label_path: /home/work/PretrainedModel/train_list.txt # 数据预处理
transform_ops:
- DecodeImage:
to_rgb: True
channel_first: False
- RandCropImage:
size: 224
- RandFlipImage:
flip_code: 1
- NormalizeImage:
scale: 1.0/255.0 mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
order: ''
batch_transform_ops:
- MixupOperator:
alpha: 0.2
sampler:
name: DistributedBatchSampler batch_size: 64
drop_last: False
shuffle: True
loader:
num_workers: 0
use_shared_memory: True
Eval:
dataset:
name: ImageNetDataset # 数据集根路径
image_root: /home/work/data/${dataset_id}
# 前面生产得到的训练集列表文件路径
cls_label_path: /home/work/PretrainedModel/val_list.txt transform_ops:
- DecodeImage:
to_rgb: True
channel_first: False
- ResizeImage:
resize_short: 256
- CropImage:
size: 224
- NormalizeImage:
scale: 1.0/255.0 mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
order: ''
sampler:
name: DistributedBatchSampler batch_size: 64
drop_last: False
shuffle: False
loader:
num_workers: 0
use_shared_memory: TrueInfer:
infer_imgs: docs/images/whl/demo.jpg batch_size: 10
transforms:
- DecodeImage:
to_rgb: True
channel_first: False
- ResizeImage:
resize_short: 256
- CropImage:
size: 224
- NormalizeImage:
scale: 1.0/255.0 mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
order: ''
- ToCHWImage:
PostProcess:
# 输出的可能性最高的前topk个
name: Topk topk: 5
# 前面得到标签文件
class_id_map_file: /home/work/PretrainedModel/label_list.txtMetric:
Train:
Eval:
- TopkAcc:
topk: [1, 5]根据相关文件的地址对上述yaml文件进行修订,主要修改点:类别数、训练和验证集的路径、标签文件地址、训练和验证的 num_workers 需修改为 0。
注:Notebook 因为是单卡的,需要将 num_workers 改为0,在本地的话则需要根据实际情况进行更改
修改类别数20行:class_num: 5修改训练集的路径(数据集id根据您自己的情况调整)49行:image_root: /home/work/data/30227350行:cls_label_path: /home/work/PretrainedModel/train.txt 修改训练GPU74行:num_workers: 0修改验证集的路径(数据集id根据您自己的情况调整)80行:image_root: /home/work/data/30227381行:cls_label_path: /home/work/PretrainedModel/val.txt 修改验证GPU101行:num_workers: 0修改标签文件地址124行:class_id_map_file: /home/work/PretrainedModel/label_list.txt
3、训练模型。
在终端中执行以下命令,开始模型训练。
cd PaddleClas-release-2.3/ python tools/train.py -c ./ppcls/configs/ImageNet/ResNet/ResNet50_vd.yaml
4、模型预测。
在终端中执行以下命令,开始模型预测。
推荐:TOP云智能建站优惠活动,仅880元即可搭建一个后台管理五端合一的智能网站(PC网站、手机网站、百度智能小程序、微信小程序、支付宝小程序),独享百度搜索SEO优势资源,让你的网站不仅有颜值有排面,更有排名,可以实实在在为您带来效益,请点击进入TOP云智能建站>>>,或咨询在线客服了解详情。
 湘公网安备43019002001857号
湘公网安备43019002001857号 备案号:
备案号: 客服1
客服1 