



喜讯:国内、香港、海外云服务器租用特惠活动,2核/4G/10M仅需31元每月,点击抢购>>>
百度智能云全功能AI开发平台BML-基于 Notebook 的 NLP 通用模板使用指南
基于 Notebook 的 NLP 通用模板使用指南
本文采用模板中预置的文心套件开发文本分类-单文本单标签模型的过程为例,介绍在使用 NLP 模板时,从创建 Notebook 任务到引入数据、训练模型,再到保存模型、部署模型的全流程。
创建并启动Notebook
1、在 BML 左侧导航栏中点击『Notebook』
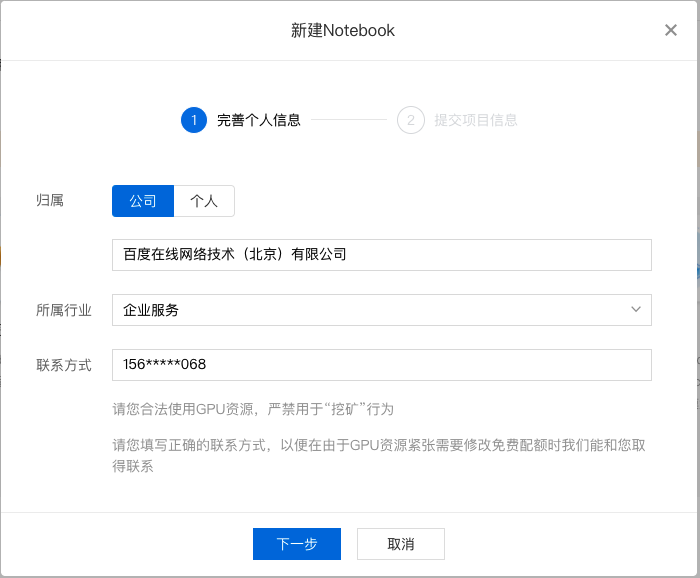
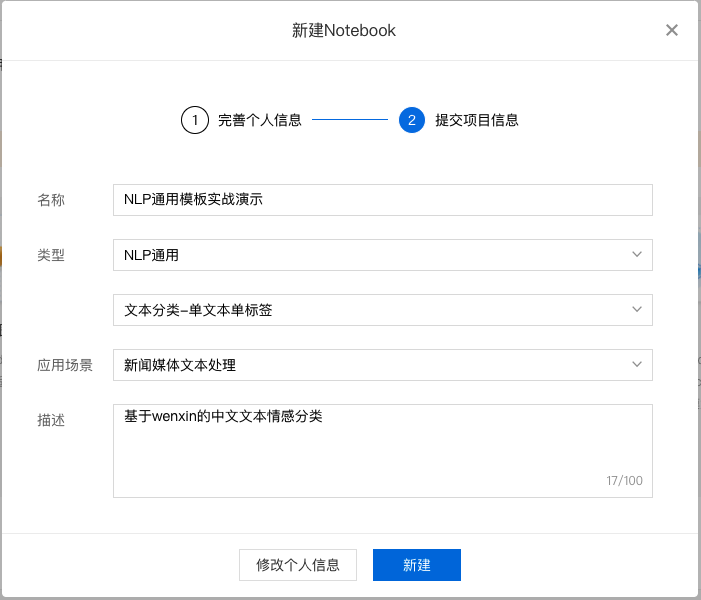
2、在 Notebook 页面点击『新建』,在弹出框中填写公司/个人信息以及项目信息,示例如下:
填写基础信息
填写项目信息
3、对 Notebook 任务操作入口中点击『配置』进行资源配置,示例如下:
选择开发语言、AI 框架,由于本次采用 wenxin 进行演示,所以需要选择 python3.7、PaddlePaddle2.0.0。选择资源规格,由于深度学习所需的训练资源一般较多,需要选择GPU V100的资源规格。
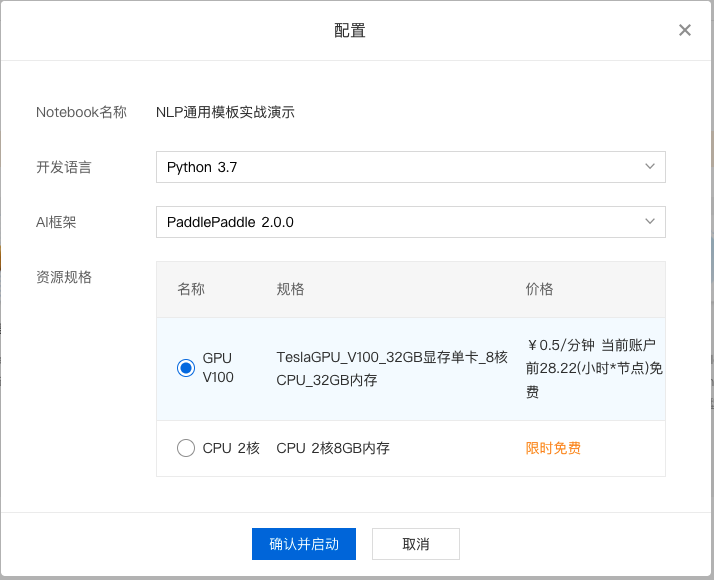
完成配置后点击『确认并启动』,即可启动 Notebook,启动过程中需要完成资源的申请以及实例创建,请耐心等待。
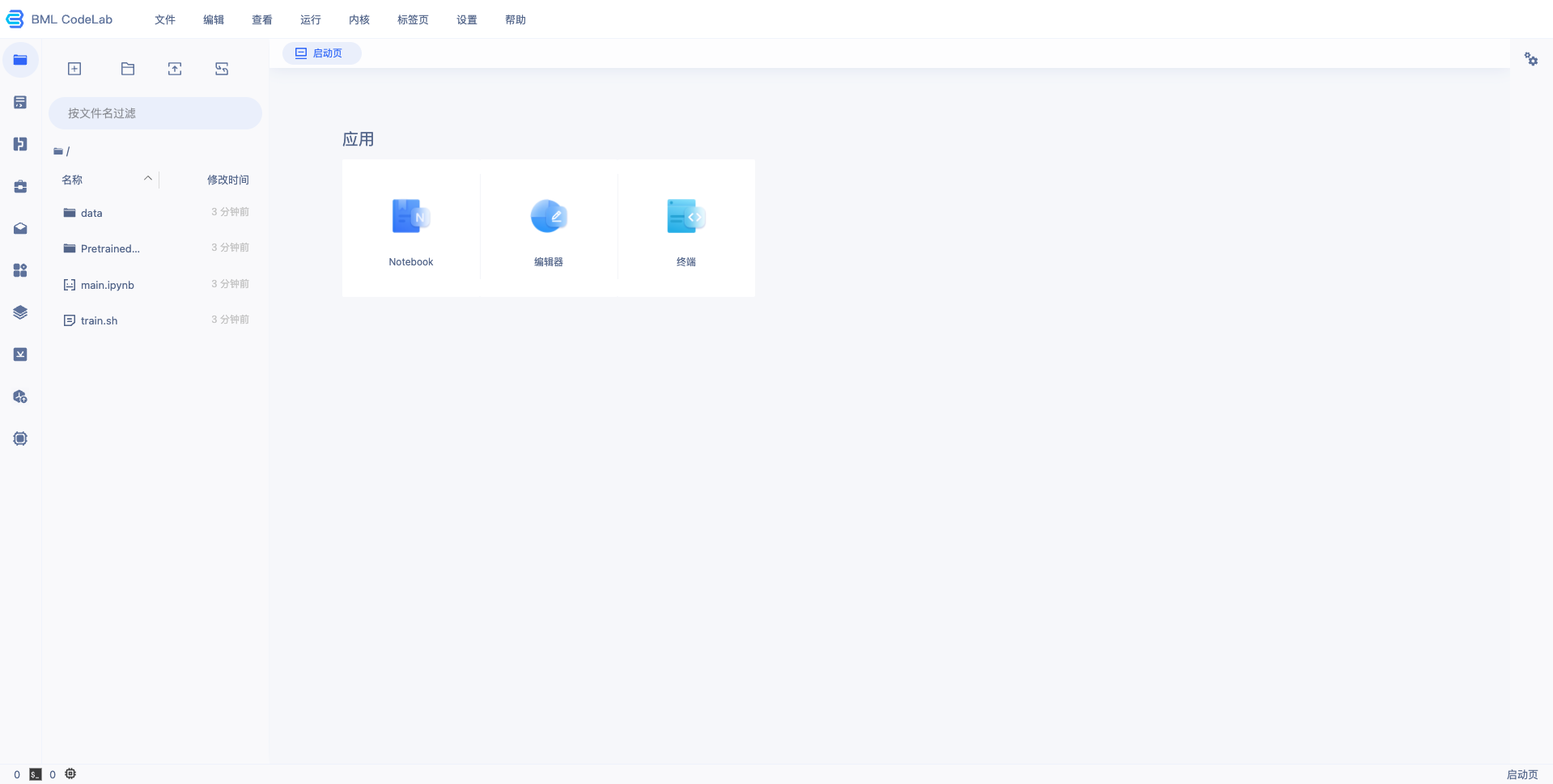
4、等待 Notebook 启动后,点击『打开』,页面跳转到 Notebook,即完成 Notebook 的创建与启动,示例如下:
训练文本分类-单文本单标签模型
下载文心套件
打开进入 Notebook,在左侧包管理插件找到 wenxin,点击安装最新版本。
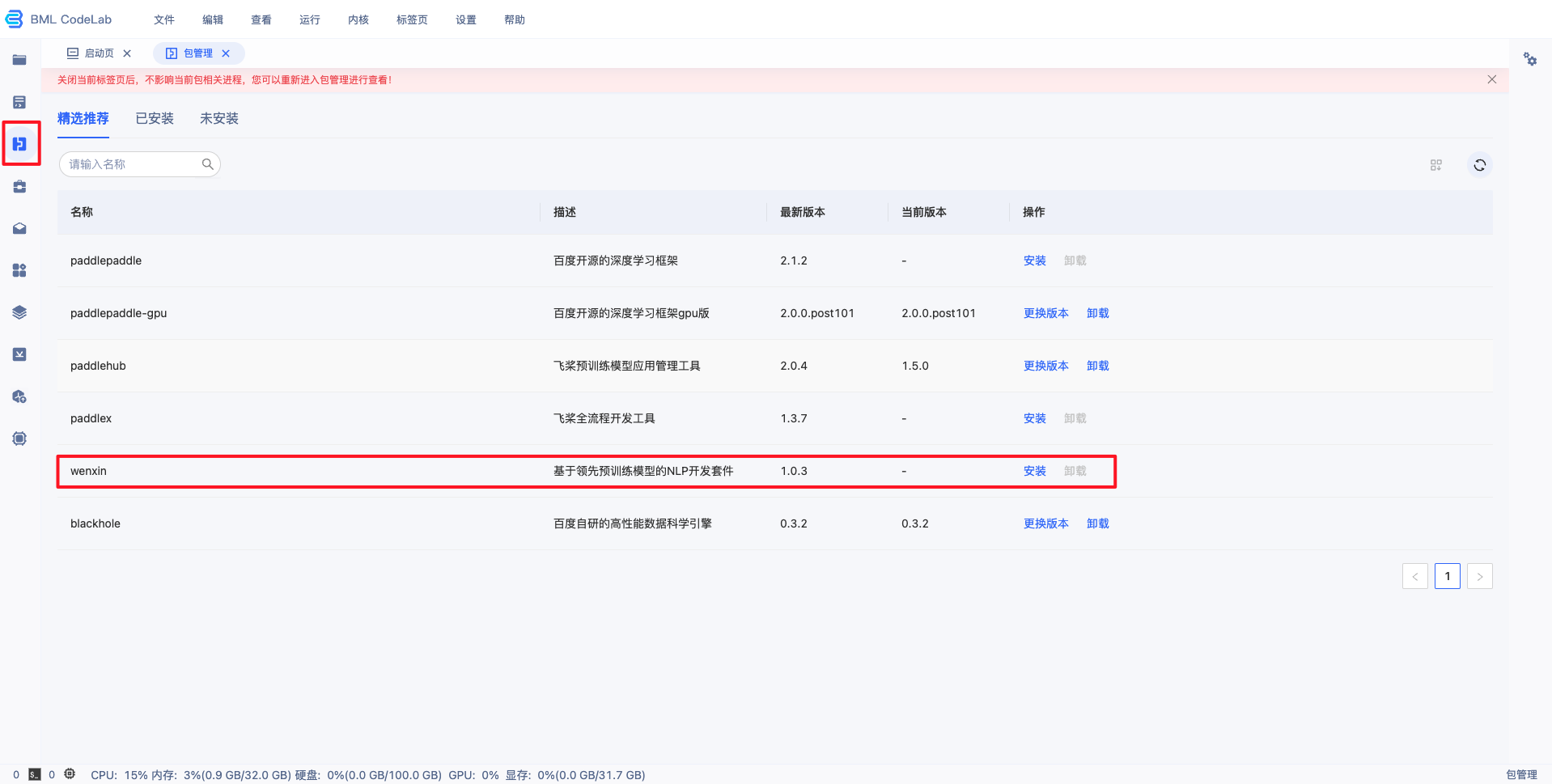
安装成功后,回到用户当前目录,即可看到 wenxin 文件夹。
准备训练数据
1、数据来源一:导入用户数据。
通过左边选择栏的导入数据集选项,进行数据集导入。导出的数据位于用户目录的 data/ 文件夹。
2、数据来源二:使用 wenxin 套件自带的数据集。
训练模型
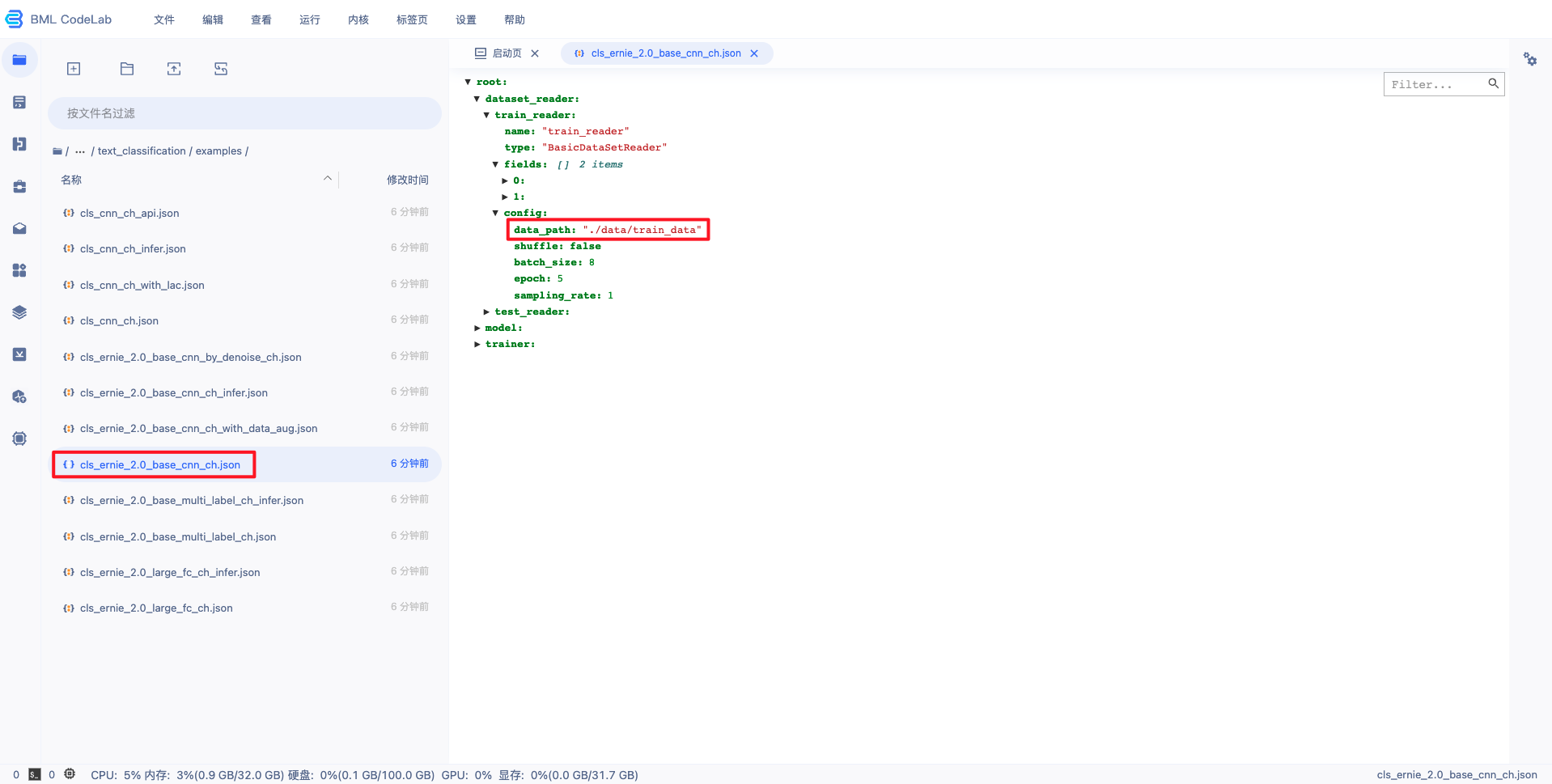
1、若需要使用用户导入的数据集,则需要更改训练的配置文件中的数据集路径。
例如使用wenxin/tasks/text_classification/examples/cls_ernie_2.0_base_cnn_ch.json配置文件,则使用 vim 进行编辑,修改 data_path。
2、下载预训练模型,在终端中执行命令如下:
cd wenxin/tasks/model_files/ bash download_ernie_2.0_base_ch.sh
3、模型训练。
cd ../text_classification python run_with_json.py --param_path examples/cls_ernie_2.0_base_cnn_ch.json
训练完成后会在该目录中生成 output 文件夹,里面存放了训练生成的模型。

4、模型拷贝,由于生成模型版本的组件只能读取 PretrainedModel 文件夹下的文件,所以需要将模型部署相关的文件都拷贝至该文件夹下。
在终端中执行命令,将模型拷贝至 PretrainedModel 文件夹下。
cp output /home/work/PretrainedModel/ -r
拷贝训练参数配置 cls_ernie_2.0_base_cnn_ch.json 中 reader 的 vocab 和 embedding.config_path 指定的文件,以便用于后续的公有云部署。
cp ../model_files/config/ernie_2.0_base_ch_config.json /home/work/PretrainedModel/ernie_2.0_base_ch_config.json cp ../model_files/dict/vocab_ernie_2.0_base_ch.txt /home/work/PretrainedModel/vocab.txt cp output/cls_ernie_2.0_base_cnn_ch/save_inference_model/inference_step_126_enc/infer_data_params.json /home/work/PretrainedModel/infer_data_params.json
5、生成模型版本。
点击左侧导航栏中的生成模型版本组件,打开弹窗填写信息。
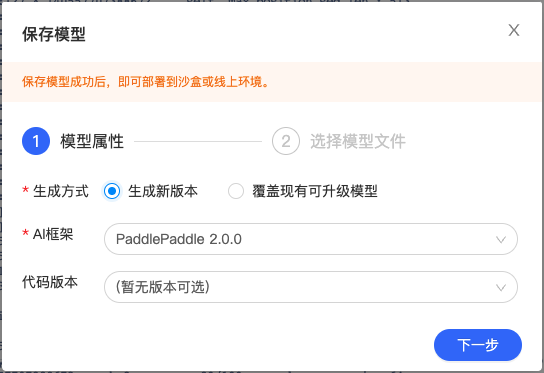
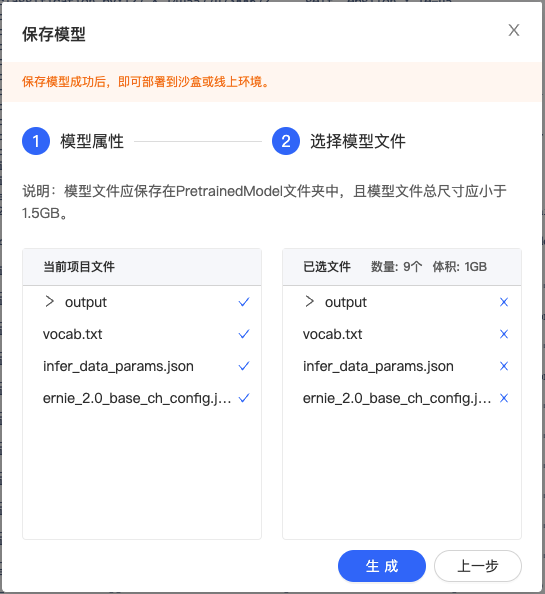
点击『生成』即可生成模型版本,生成模型版本一般需要数十秒,请耐心等待。
配置并发布模型
BML NoteBook 的 NLP 通用模板产出的模型支持基于百度自研的PaddlePaddle深度学习框架和文心套件进行开发的文本分类-单文本单标签、文本分类-单文本多标签、短文本相似度、序列标注四种应用方向的模型进行部署。下面以文本分类-单文本单标签的模型为例,详细介绍如何配置模型:
1、查看前置条件是否满足:需要训练完成,并生成了相应的模型生成版本(详见训练模型的第五步)。
2、回到 BML Notebook 列表页,点击『模型发布列表』即可进入配置页面。

3、点击配置,即可进入配置流程。

4、填写模型信息。

5、选择待发布的模型文件,点击确定按钮。

其中:vocab.txt 为词表文件,output为模型文件,ernie_2.0_base_ch_config.json 和 infer_data_params.json 为配置文件,非必须。
6、配置出入参及数据逻辑处理。
点击立即编辑,即可进入代码编辑页面。主要需要修改 vocab_path 和 inference_model_path 两个字段的路径为所选择的路径(注:『选择模型文件』后的模型文件将存放在系统制定的路径下,用户在代码中可直接采用相对路径,如 vocab.txt 文件的路径为 ./vocab.txt ,output 文件夹的路径为 ./output)。
在本次示例中, vocab_path 默认路径就是所选择的路径,无须修改,仅需要修改inference_model_path即可。

修改为:

最终的代码如下:
{
"dataset_reader": {
"predict_reader": {
"name": "predict_reader",
"type": "BasicDataSetReader",
"fields": [
{
"name": "text_a",
"data_type": "string",
"reader": {
"type": "ErnieTextFieldReader"
},
"tokenizer": {
"type": "FullTokenizer",
"split_char": " ",
"unk_token": "[UNK]"
},
"need_convert": true,
"vocab_path": "./vocab.txt",
"max_seq_len": 512,
"truncation_type": 0,
"padding_id": 0,
"embedding": {
"type": "ErnieTokenEmbedding",
"use_reader_emb": false,
"emb_dim": 768,
"config_path": "ernie_2.0_base_ch_config.json"
}
}
],
"config": {
"data_path": "./data/predict_data",
"shuffle": false,
"batch_size": 8,
"epoch": 1,
"sampling_rate": 1.0
}
}
},
"inference": {
"output_path": "./output/predict_result.txt",
"inference_model_path": "./output/cls_ernie_2.0_base_cnn_ch/save_inference_model/inference_step_126_enc",
"PADDLE_USE_GPU": 1,
"PADDLE_IS_LOCAL": 1,
"num_labels": 2,
"extra_param": {
"meta":{
"job_type": "text_classification"
}
}
}
}配置文件对于服务部署来说包括两个部分: dataset_reader(数据部分)和 inference 部分,相关字段的解释如下表所示:
dataset_reader 数据部分
{
"dataset_reader": {
"predict_reader": { ## 预测推理,则必须配置predict_reader,其配置方式与train_reader、test_reader类似,需要注意的是predict_reader不需要label域,shuffle参数必须是false,epoch参数必须是1。
"name": "predict_reader",
"type": "BasicDataSetReader", ## 采用BasicDataSetReader,其封装了常见的读取tsv、txt文件、组batch等操作。
"fields": [ ## 域(field)是文心的高阶封装,对于同一个样本存在不同域的时候,不同域有单独的数据类型(文本、数值、整型、浮点型)、单独的词表(vocabulary)等,可以根据不同域进行语义表示,如文本转id等操作,field_reader是实现这些操作的类。
{
"name": "text_a", ## 文本分类只有一个文本特征域,命名为"text_a"。
"data_type": "string", ## data_type定义域的数据类型,文本域的类型为string,整型数值为int,浮点型数值为float。
"reader": {
"type": "ErnieTextFieldReader" ## 文本域的通用reader "CustomTextFieldReader",数值数组类型域为"ScalarArrayFieldReader",数值标量类型域为"ScalarFieldReader",这里的取值是对应FieldReader的类名
&a
推荐:TOP云智能建站优惠活动,仅880元即可搭建一个后台管理五端合一的智能网站(PC网站、手机网站、百度智能小程序、微信小程序、支付宝小程序),独享百度搜索SEO优势资源,让你的网站不仅有颜值有排面,更有排名,可以实实在在为您带来效益,请点击进入TOP云智能建站>>>,或咨询在线客服了解详情。
 湘公网安备43019002001857号
湘公网安备43019002001857号 备案号:
备案号: 客服1
客服1 